AI Product Tools Compared: My 2026 Stack Picks

Last spring I tried to run a roadmap refresh with “just one more tool” and ended up with five tabs, three logins, and a Slack thread that aged me a full year. That mini-mess sent me on a slightly obsessive mission: compare AI product management tools the way we actually use them—under deadline, mid-meeting, and with someone asking, “Can we ship this by Friday?” This guide is my opinionated, field-notes-style breakdown of AI-powered solutions across planning, build, feedback, and the unglamorous but crucial world of monitoring.
The messy truth: why “best” tools fail in real life
I learned this the hard way while testing the Best AI tools 2026 lists from “Ultimate Product Tools Compared: AI-Powered Solutions.” I ended up with an accidental “five-tab” workflow: analytics, feedback, roadmap, docs, and project tracking all open at once. My self-score was simple: 5 tabs = high friction. I wasn’t slower because the tools were “bad”—I was slower because my brain kept paying the context-switching tax.
| Context switching cost (self-score) | What it felt like |
|---|---|
| 5 tabs | High friction |
| 2 tabs | Manageable |
| 1 tab | Ideal |
My rule now: one tool per job, but Project management integration must do the glue work
Integration capabilities between tools are crucial for ROI. The stack only pays off when my quantitative analytics connects cleanly to qualitative feedback, so decisions aren’t split across systems. That’s also why I care more about Project management integration than fancy dashboards.
Teresa Torres: “Continuous discovery only works when insights move as fast as delivery.”
When AI-powered productivity recommendations help (and when they add noise)
In AI product management tools, AI is best when it reduces clicks. ClickUp’s natural language questions help me find work fast. Wrike’s predictive risk analysis is useful when timelines are real. Asana’s productivity recommendations can be great—until they become extra alerts I ignore. My filter: if AI doesn’t change my next action, it’s noise.
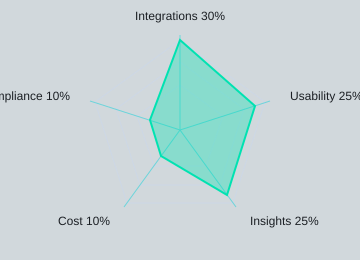
How I score tools (example weights)
| Criteria | Weight |
|---|---|
| Integrations | 30% |
| Usability | 25% |
| Insights quality | 25% |
| Cost | 10% |
| Compliance | 10% |
Wild-card analogy + quick checklist
Picking tools is like packing for a trip—bring layers, not duplicates. I’d rather have one strong system with Real-time collaboration features and solid Security compliance safeguards, plus integrations, than three overlapping apps.
- Security compliance safeguards: SSO, audit logs, data controls
- Real-time collaboration features: comments, live docs, shared views
- Cost tracking optimization: seat creep checks, usage reports, ROI notes

AI product management tools for roadmaps (and the arguments they prevent)
AI product management tools
In my 2026 stack, AI product management tools earn their keep when they turn “loud opinions” into visible tradeoffs. In product roadmap planning, “AI prioritization” is not magic. In practice, it’s a set of inputs pulled from feedback sources and analytics platforms, then ranked with a custom model so the team can debate weights, not feelings.
Marty Cagan: “It’s not about ideas. It’s about solving problems for customers in a way that works for the business.”
Roadmap planning tools compared
When I do Roadmap planning tools compared reviews, I look for three AI behaviors: (1) suggested priority based on my scoring rules, (2) predictive timelines with scenarios, and (3) links from features to OKRs so we stop shipping “busy work.”
Standout features comparison.
For a quick Standout features comparison, I focus on:
- Custom scoring models (my default weights below)
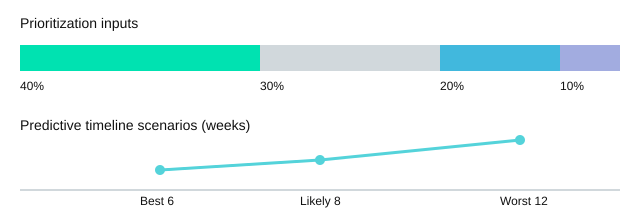
- Predictive timelines: Best case 6 weeks; Likely 8; Worst 12
- OKR linking and customizable dashboard metrics for exec updates
My Friday “priority reset” (feature prioritization scoring)
Every Friday I run a 20-minute “priority reset” using feature prioritization scoring. Last quarter, a stakeholder meeting was stuck on “big logo request vs core UX fix.” I pulled up the scoring model, adjusted one assumption (revenue impact), and the debate cooled fast because everyone could see the math.
Customer pain 40% + Revenue impact 30% + Effort 20% + Risk 10%
Productboard feedback aggregation vs dumping ground
Productboard feedback aggregation helps when I enforce tags, dedupe rules, and link insights to outcomes. Without that, it becomes a dumping ground of raw notes that AI can summarize—but not truly prioritize.
Airfocus data-driven prioritization for transparency
Airfocus data-driven prioritization is my pick when stakeholders demand transparency: they can inspect the model, the inputs, and the “why” behind each rank. If you manage multiple products, you’ll want portfolio views—this is where I start thinking about Airtable ProductCentral.
| Input | Value |
|---|---|
| Customer pain | 40% |
| Revenue impact | 30% |
| Effort | 20% |
| Risk | 10% |
| Timeline (best/likely/worst) | 6 / 8 / 12 weeks |
Analytics tools product decisions: marrying numbers with feelings
I make better Analytics tools product decisions when I pair a chart with five angry support tickets. Once, my dashboard said activation was “fine,” so I pushed a launch harder. Then I read the tickets: people were stuck on one confusing step. The metric wasn’t lying—I was just looking at it without context. As April Dunford puts it: “The secret to positioning is really just context—what you compare yourself to changes everything.”
Customer feedback analysis: AI themes without losing nuance
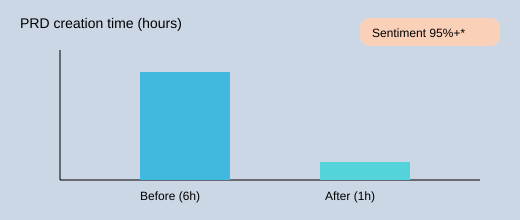
My favorite workflow is Customer feedback analysis first, numbers second. Modern research tools can synthesize themes with 95%+ sentiment analysis accuracy (reported), and that speed matters. Before AI synthesis, my PRD drafts took 4–8 hours. Now I can get a solid first PRD in under one hour, then spend my time validating instead of copy-pasting quotes. I still read raw verbatims—AI helps me sort, not decide.
Behavioral analytics churn prediction: shine vs overpromise
Behavioral analytics churn prediction shines when it flags patterns like “users who skip onboarding step 2 churn 3× more.” It overpromises when teams treat a churn score like fate. I use it as a question generator: Why are they dropping? Then I confirm with interviews, tickets, and NPS comments. The best teams I’ve seen run this quant + qual loop fast, turning insight into a validated solution without waiting weeks.
Customizable dashboard metrics I keep during launches
- Activation rate
- Day-7 retention
- Support ticket volume
- NPS verbatims count
These Customizable dashboard metrics fit on one screen so I can spot movement, then jump straight into the “why.”
A small tangent: when sentiment accuracy surprised me
I once assumed sentiment models would miss sarcasm. They didn’t—at least not often. Seeing that 95%+ number match my manual spot-checks was the moment I started trusting AI-powered insights recommendations as a starting point, not a shortcut.
| Metric | Value |
|---|---|
| Sentiment analysis accuracy | 95%+ (reported) |
| PRD creation time | Before: 4–8 hours; After AI: <1 hour |
| Launch dashboard set | Activation rate, Day-7 retention, Support ticket volume, NPS verbatims count |
“The secret to positioning is really just context—what you compare yourself to changes everything.” — April Dunford

From idea to prototype: Cursor GitHub Copilot, Vercel v0, Replit Agent
In my 2026 workflow, AI tools product managers use go beyond docs: I lean on Best AI tools for code editing and app generation to turn a fuzzy idea into something users can click.
Cursor GitHub Copilot
When I need “first draft” rights, I choose based on where the uncertainty lives. If I’m exploring a new codebase and want fast refactors plus chat that understands context, I start in Cursor GitHub Copilot-style editors. If I’m already confident in the architecture and just want steady inline suggestions, Copilot often wins. Either way, I treat the output as a draft, not truth.
Vercel v0 Replit Agent
Vercel v0 Replit Agent is where the demo becomes (or fails to become) a deployable prototype. v0 shines when I want a clean UI scaffold fast; Replit Agent shines when I want an end-to-end runnable app with minimal setup. The honest warning: these tools can produce demo-ware—screens that look real but hide missing auth, edge cases, or data flows.
Kent Beck: “Make it work, make it right, make it fast.”
My rule of thumb: optimize for learning speed in MVP week, not code perfection. I’ll worry about API latency and error rates later, once the prototype proves demand and we start monitoring for real.
Phase MVP scale planning.
Phase MVP scale planning changes the tool mix as soon as real users show up: validation (1–2 weeks), MVP build (2–6 weeks), then scale hardening (4–12 weeks). As usage grows, I shift from “generate fast” to “make stable.”
- 48-hour scenario: Day 1: v0 generates a landing page + onboarding UI; I wire basic events and copy. Day 2: Replit Agent connects auth + a simple database, then I deploy and test the full flow.
| Stage | Timebox |
|---|---|
| Prototype sprint | 48 hours |
| Idea validation | 1–2 weeks |
| MVP build | 2–6 weeks |
| Scale hardening | 4–12 weeks |

Prompt management platform choices: LangSmith prompt management vs Humanloop evaluation monitoring
In 2026, I treat a Prompt management platform like a mini product org. Prompt work feels like product work because it has versioning, regressions, and real stakeholder expectations (“don’t change the tone,” “don’t break onboarding,” “keep costs flat”). As Andrew Ng said, “AI is the new electricity.” That also means small prompt changes can ripple through everything.
LangSmith prompt management
When I look at LangSmith prompt management-style features, I focus on what I can track on day one:
- Prompts: versions, owners, and what changed (diffs)
- Runs: inputs/outputs, latency, token usage, and failures
- Datasets: saved test cases that reflect real user flows
This is the foundation for AI-powered insights recommendations later, because you can’t improve what you can’t replay.
Humanloop evaluation monitoring
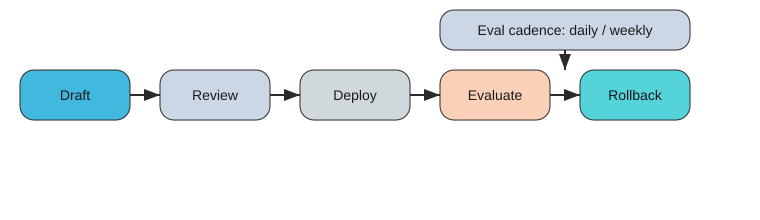
I reach for Humanloop evaluation monitoring-type capabilities the moment I need evals, not vibes. An eval harness is simply a repeatable test suite: fixed prompts + datasets + scoring (human or automated) so I can compare versions safely. My cadence example: Daily during launch week; Weekly after stabilization.
My tiny “oops” story: I once tweaked a system prompt to “sound more friendly.” It quietly broke onboarding copy in three languages—Spanish got too informal, German got oddly long, and Japanese lost key steps. If I’d had consistent evals and monitoring, I would’ve caught it before deploy.
This connects directly to PRD creation automation: modern customer research and feedback analysis tools can cut PRD time from 4–8 hours to under one hour, but only if prompt changes ship safely and fast. Once prompts go live, I also want tracking plus cost visibility—so observability isn’t optional.
| Prompt lifecycle stages (5) | Evaluation cadence (example) |
|---|---|
| Draft, Review, Deploy, Evaluate, Rollback | Daily during launch week; Weekly after stabilization |

LLM observability tracking: Helicone + Datadog New Relic APM (yes, both)
In my 2026 stack, LLM observability tracking is product work, not just engineering. If users feel lag, see weird answers, or hit errors, they churn—and trust is hard to win back. As the “Ultimate Product Tools Compared: AI-Powered Solutionsundefined” theme suggests, AI product management tools in 2026 now include specialized solutions for LLM observability (Helicone), because classic APM alone can’t explain model behavior.
Charity Majors: “Observability lets you ask questions you didn’t know you needed to ask.”
Helicone LLM observability
Helicone LLM observability is where I look for what I want visible before a customer reports it: prompt/version changes, model routing, token spikes, and which user flows trigger bad outputs. I tag requests by feature, cohort, and experiment so I can connect quality and cost to product decisions.
Datadog New Relic APM.
Datadog New Relic APM is still where classic monitoring wins: infra health, distributed traces, queue depth, and alerting. When API latency error rates jump, APM tells me if it’s the gateway, a DB call, a cache miss, or a provider timeout.
- API latency error rates: the boring metric that quietly decides retention.
- Cost tracking optimization: I treat spend like an SLO, not an afterthought.
| Area | Example targets |
|---|---|
| SLOs | p95 latency 800ms; error rate 1%; uptime 99.9% |
| Cost guardrails | $200/day warning; $500/day hard stop |
| Incident response | Detect <5 min; Acknowledge <15 min; Mitigate <60 min |
Wild-card thought experiment: if your AI feature went viral overnight, what breaks first—rate limits, token spend, or downstream services? My answer is “all three,” so I wire Helicone + APM alerts to the same on-call channel.
Stack comparison team size: solo PM to enterprise (my biased shopping list)
When I do a Stack comparison team size exercise, I start with one rule: buy clarity before you buy features. As Julie Zhuo says, “Good managers create clarity.” That’s the job, whether you’re a solo PM or running a large org with many product lines.
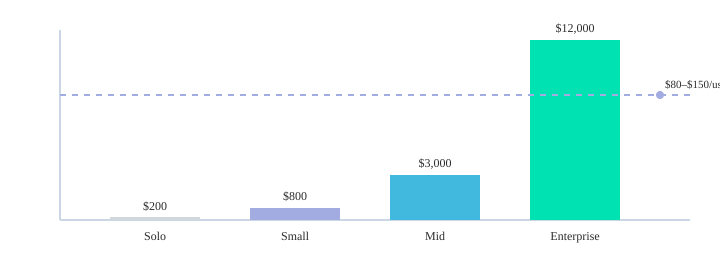
Solo (1): my ~$200/month “complete workflow” (and what I’d skip)
If I’m a solo PM, I’d keep it tight: BuildBetter for Meeting intelligence automation, Notion AI for docs/specs, and Linear for execution. This trio can cover discovery notes, decisions, and delivery for about $200/month. What I’d skip early: heavy portfolio suites and expensive “all-in-one” platforms that lock you into $80–$150/user/month before you even have a team.
Small (2–10) and mid (11–50): best AI agile project management depends on risk
For small teams, I still like Linear plus Notion AI, but I add integrations only when they reduce risk: customer feedback intake, analytics, and a lightweight roadmap view. For mid-size teams, the “Best AI agile project management” tool is the one that connects planning to delivery without extra meetings—especially if you ship across multiple squads.
Enterprise (50+): Airtable ProductCentral for product portfolio management
At enterprise scale, Airtable ProductCentral earns its keep because Product portfolio management becomes the real problem: centralizing roadmaps, tracking OKRs, improving resource allocation, and automating coordination across product lines. That’s where customization and governance matter more than “cool AI.”
Pricing reality check + meeting intelligence automation
Most AI product management tools start with free plans and basic analytics, then jump to enterprise tiers around $80–$150/user/month with customization and dedicated support. I also budget for meeting capture: meeting intelligence tools can mine 8–12 weekly meetings, which is where the real product signals hide.
| Metric | Value |
|---|---|
| Pricing range | Free plans → $80–$150/user/month enterprise |
| Solo stack budget | ~$200/month |
| Meetings captured/week | 8–12 |
| Team sizes | Solo 1; Small 2–10; Mid 11–50; Enterprise 50+ |
My recommendation framework is simple: pick tools based on phase (discovery vs delivery), risk (compliance and coordination), integrations (where data must flow), and budget. If you do that, your stack stays lean when you’re small, and it scales only when the work truly demands it.
TL;DR: If you’re picking AI product management tools in 2026, don’t chase the “best” single app—build a small, connected stack. Use AI roadmap planning + feedback synthesis to cut PRD time under 1 hour, add prompt management + LLM observability as soon as you ship AI features, and choose pricing that matches your team size ($200/month solo stacks vs $80–$150/user/month enterprise).


Comments
Post a Comment